Identity System Architectures
I deeply believe that practically every business runs a few identity systems. Identity is unavoidable. Sometimes you need to be made aware that you manage an identity system.
Some examples of identity could be quite uncommon.
- Online or offline event tickets
- order receipts
We should rethink identity as a relation, not personalities or users.
Well, today, we will focus on broader categories of identity systems.
Such a quick categorisation of identity systems based on the root of trust
- Administrative
- Algorithmic
- Autonomic
Administrative
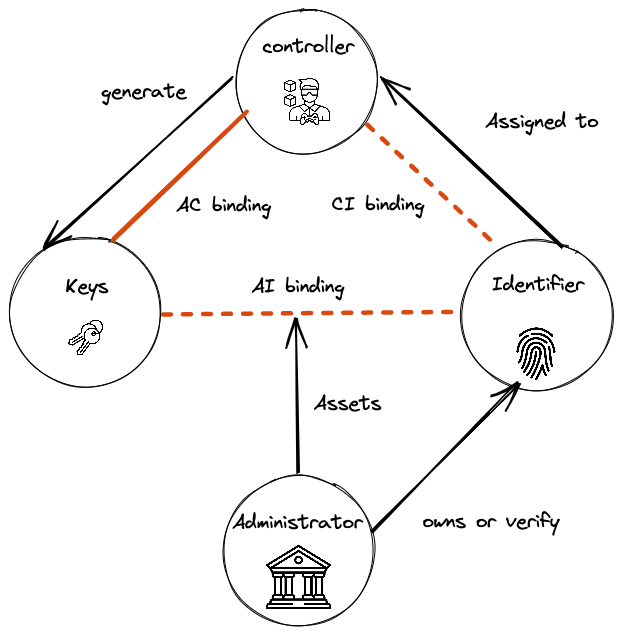
The total and almost exclusive majority of modern identity is Administrative identity. Administrator founds trust basis. An administrator could be a person, organization, or system managed by organizations. In an administrative system, an identifier could be issued or owned by the Administrator or could be owned by another system. Still, it is bonded — assigned by the administrator to the controller (user). So controller-identifier or AI binging is weak and controlled by the administrator. In such systems, keys could be a password or MFA authentification factor.
The source of truth is an administrative database that stores an identifier to controller bindings.
Quite often, this system is centralized and owned by Organisations.
SSI Identity Systems
SSI systems introduce a completely different approach as an alternative to Administrative systems. First of all, network effects in such systems play a key role. Every member of a system has equal rights. The controller has full ownership of his identity. Such systems have an interconnected mesh of sovereign administrators.
One of the key challenges in such systems is the root of trust. Roots of trust derive a key difference in the next 2 Architectures.
The key concept is not decentralization — it is only an implementation detail. Key of SSI identity systems is sovereignty and user control of identity.
Algorithmic
Relay on Verified Data Registry.
VDR is publicly open for reading and discovery.
VDR has an algorithmic and protocol-driven architecture which means it is controlled algorithmically based on open standards and public algorithms. In rare cases, it could be centralized and managed by the organization but still follow open standards.
The more preferred way is decentralized distributed consensus-based data storage.
It could be public or permission blockchains—some blockchains designed for identity only, like hyper ledger Indy or similar.
In Algorithmic systems, keys usually mean asymmetric cryptography key pairs. The controller generates a key pair and registers a public key in a VDR. Everybody can access a VDR and retrieve public keys based on the identifier. In the best-case scenario, an identifier is cryptographically derived from a key pair or the same cryptographic material.
The majority of blockchain DID methods are a perfect example of VDR. VDR could store much more than public keys or identifier bindings. VDR is a key enabler in AnonCreds Verifiable credentials that enable ZKP credentials to store VC schemas, blind links, VC metadata, and public information about issuers together with a revocation list, etc.
In the case of did: corporate web domain, a website could act as a primitive centralized VDR.
Any DTL and decentralized file systems like IPFS could be used as VDRs.
VDR is a bit more than storage it brings governance and policies that enable trust and regulation in the network

Autonomic
Similar to Algorithmic in a flow but completely self-administrated and self-certified. Cryptographic material owned by the controller still drives the identifier. All bindings between an identifier, controller, and identifier govern by a protocol and recorded in a controller Key event log.
The key difference here — we eliminate a VDR and replace it with co-local architecture owned and run by the controller. As a result, we get a high-scale, resistant, autonomic system that could operate without any third-party services.
In this case, the root of trust is self-certified by the controller. It creates a question should we trust and rely on self-certified data? A few tries to create self-certified systems in the past failed to build trust relations. That's why it is critical to creating open to audit end-to-end verifiable systems and protocols that could create a network of trust. Such systems could involve witness networks and network participants' cross-verification of key event logs.
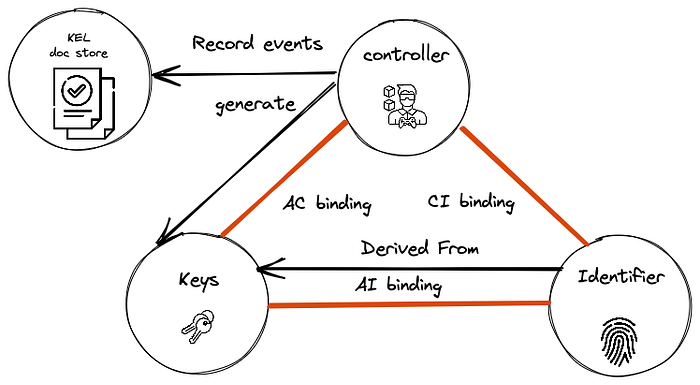
AIDs or autonomous DIDs fail in this bucket well together with the KERI protocol.
You can read more about AID in my article.
And discover DID:Web as a simplified AID for organizations
All key event logs or did document storages for did:peer is some form of co-local storages that still require end-to-end verifiability. You can discover more about micro ledgers
The pioneer and most matured solution now for autonomic identity systems infrastructure is KERI
It is still a lot of work in adoption of SSI identity systems but i see a stable trand in this space.
